Just made a weekly backup script of Image-Charts @Cloudflare DNS settings in BIND format.
It's based on flares and Gitlab CI pipeline schedules & artifacts
Find the 3-steps tutorial and .gitlab-ci.yml file here
Just made a weekly backup script of Image-Charts @Cloudflare DNS settings in BIND format.
It's based on flares and Gitlab CI pipeline schedules & artifacts
Find the 3-steps tutorial and .gitlab-ci.yml file here
Depuis juin dernier je souhaitais vous proposer un feedback sur le talk Choisir entre une API RPC, SOAP, REST, #GraphQL et si le problème était ailleurs ? qui avait eu lieu au Web2Day à Nantes.
Comme le veut la coutume, j'en ai profité pour partager quelques stickers d'Image-Charts et de Redsmin!
Ready for @web2day #Nantes! pic.twitter.com/5zukioNBEp
— François-G. Ribreau (@FGRibreau) May 16, 2018
Bien que le sujet soit touchy — s'attaquer à la doxa concernant les SGBDR et essayer de montrer qu'il y a d'autres voies n'était pas gagné d'avance —, les réactions ont été très positives !
Meilleure conférence de tout le #web2day #blowmymind https://t.co/GBtLDwWGmW
— Guillaume Cisco (@GuillaumeCisco) June 15, 2018
Je confirme : l’une des meilleures conf. sur les API ever.
— Thierry Gaillet (@ThyGat) June 16, 2018
Tant sur le fond, la doctrine, le rappel des fondamentaux.
Que sur la forme : directe, décapante et soutenue.
Cela mériterait un long article dans Médium par ex.
Bravo.
Excellente présentation de @FGRibreau, j'en ressors grandi. Fini l'ère de la duplication d'informations. Aujourd'hui nous devons nous concentrer d'avantage sur la couche data qui offre des multitudes de possibilités.
— Laurent Thiebault 🚀 (@lauthieb) July 10, 2018
Si vous avez 35min, foncez ! 🚀 https://t.co/cIilNFCnhv
Talk très inspirant sur les #API par @FGRibreau : https://t.co/yV2XemlMS6#postgresql est un outil formidable 😍
— Cyril Delmas 🐧🍺 (@cyril_delmas) July 12, 2018
Merci de prêcher cette "database-centric philosophy" 👍 ! Ce n'est pas facile de faire comprendre les intérêts et les possibilités. Les RDBM tels que #PostgreSQL offrent des outils hyper puissants, trop souvent ignorés et sous-exploités.
— David Grelaud (@DavidGrelaud) June 16, 2018
Choose between RPC, SOAP, REST, #GraphQL … by @FGRibreau at #Web2Day2018 🤯 Always bet on SQL ! pic.twitter.com/uRJgsAH6XK
— Sébastien Elet (@SebastienElet) June 18, 2018
Si vous n'avez pas pu assister au Web2Day, bonne nouvelle, les replays sont disponibles sur YouTube et voici l'intervention en question :
Ce talk a aussi suscité des questions après la conférence et comme elles me sont souvent posées lorsque j'aborde ces sujets, je profite de ce billet pour y répondre afin d'y référer les prochains interlocuteurs 😁.
Comment sécuriser les appels ?
En fonction de la présence ou non de la JWT lors de l'appel ainsi que des privilèges associés aux rôles sur les vues et fonctions stockées (cf. le talk) les appels nécessiteront ou pas une authentification.
Je suis plus productif avec un ORM qu'en écrivant du SQL directement
Sans entrer dans le sujet ORM (qui d'ailleurs serait un débat passionnant), SQL est partout même là où on ne l'attend pas que cela soit en Big Data (Kafka KSQL, Spark, Flink) ou en NoSQL (Elasticsearch SQL, Cassandra CQL). Ceci pour expliciter que l'argument selon lequel un développeur n'aurait pas besoin de connaitre SQL est aussi caduque que la pensée qu'un développeur ne doit pas savoir écrire des tests ou connaitre OWASP top 10.
Les SGBDR et plus précisément PostgreSQL ont des fonctionnalités et permettent d'être déclaratif sur certaines problématiques comme la gestion des droits plutôt que de devoir re-développer à chaque projet un système from scratch. L'ORM ne résout pas le sujet des autorisations et même (c'est là où la discussion est intéressante), même si nous trouvions un ORM gérant les autorisations, le problème fondamental est qu'elles seraient gérées au niveau de la couche applicative, laissant, en cas de faille (e.g. escalade de privilège), un accès complet à la base. C'est l'intérêt de travailler sur les couches les plus basses pour avoir des leviers (ici la sécurité) sur les couches supérieures.
Quid de la gestion des droits multi-tenant et de la séparation read/write ?
Ça devient plus compliqué quand il faut différencier read/write et ajouter la gestion des droits multi-tenant.
— Thomas Poc (@thomasPoc) June 27, 2018
Gérer le multi-tenant avec une approche déclarative — en comparaison à une approche impérative — permet de respecter single-source-of-truth (il est structurellement bien plus difficile d'avoir la garantie qu'une règle d'autorisation sera appliquée — de manière future-proof — sur l'intégralité d'une code base lorsque l'on passe par du code). Dans le cas de RLS (Row Level Security), limiter un utilisateur pour qu'il ne voit que ses propres éléments dans la table X, peu importe comment elle sera accédée dans le futur (avec jointure ou pas) revient uniquement à déclarer using (user_id = request.user_id()) ou encore, pour limiter l'accès au niveau d'une organisation using (organization_id = request.organization_id()).
À noter qu'il n'est pas obligé de mettre les identifiants d'utilisateur, d'organisation ou de groupe en colonne de chaque table car ces informations sont très souvent déjà présentes au niveau de la JWT, la mise en place d'une function stable pour accéder à ces attributs à join est aussi possible et tout aussi efficace.
Pour la gestion des accès en écriture (à savoir create, update, delete), toujours en RLS, with check prend la relève et offre une approche unifiée permettant ainsi de distinguer — si souhaité — les accès entre les opérations de lecture (avec using) et d'écriture (avec with check).
Comment gérer les montées en version ?
De la même manière qu'une API doit la plupart du temps supporter N et N-1. Dans le cas d'une breaking, la montée de version nécessite d’avoir une compatibilité descendante. Cela passe (cf. le début du talk) par la mise en place d'un second schéma (e.g. v2), avec des vues et fonctions stockées qui pointent vers les schémas privés et qui retournent les données sous le nouveau format.
Il faut noter que cette notion de (1..N) schémas publiques et (1..N) schémas privés permet une flexibilité dans les développements et les itérations tout en respectant le principe de Single Source of Truth.
J'ai peur que le "code" finisse par n'être qu'une liste de scripts de migration ?
Pour compléter la réponse précédente, effectivement, il a été un temps où tout n'était que migration. Et c'est problématique car une suite de fichiers SQL représentant les migrations sont bien plus difficile à suivre qu'un ensemble de fichier SQL représentant l'intégralité de l'état final des schémas de BDD. Fort heureusement des outils apparaissent et permettent de se concentrer uniquement sur l'état final et de laisser l'outil générer les migrations entre l'état précédent et le nouvel état (cf. question ci-dessous sur "Comment bien démarrer"). Le(s) développeur(s) se concentrent donc uniquement sur sa version cible et laisse l'outil gérer les diffs. C'est une approche saine que l'on retrouve d'ailleurs dans d'autres domaines comme celui de la gestion de configuration d'infrastructure (e.g. Terraform).
Comment scale ?
Il y a deux réponses à cette question. La première concerne le scaling de l'API (PostgREST ou Subzero, ...) et ici il s'agit de scaling horizontal classique.
La seconde question qui vient juste après concerne le scaling de la base de données. Mais avant de parler de cela, il nous faut ici rappeler un point fondamental qui est souvent oublié. Sur le modèle présenté ici (API passe-plat vers la BDD), la base de données fait autant de travail que dans une approche 3 tiers, c'est même souvent (et c'est structurel) plus performant. Pourquoi ? Parce qu'au lieu de N requêtes à la BDD (authentification, autorisations, lectures ou écritures multiples) depuis une requête HTTP vers l'API, dans le modèle présent tout est résolu au sein d'une même requête, donc pas d'overhead sur l'aller/retour avec la BDD.
Ensuite, nous sommes en 2018, PostgreSQL est maintenant capable de gérer des quantités astronomiques de données (10 To chez Leboncoin par exemple). Quand je vois la taille des datasets des entreprises, dans l'immense majorité, cela ne dépasse pas la dizaine voir la centaine de Go, ce qui est un non sujet avec PostgreSQL. Encore une fois, comme je le dis dans le talk, ce style d'architecture permet de traiter environ 80% des usages en entreprise. Pour ces 80% il n'est pas nécessaire de monter un cassandra/mongodb en cluster lorsque le besoin est finalement de stocker de la donnée relationnelle (rappel : notre univers est relationnel) représentant moins de 100 Go.
Et si problème de scaling il y a, alors c'est une excellente nouvelle ! Le business aura crû progressivement (ou rapidement), l'approche DB-centric aura permis d'avoir un time-to-market très aggressif tout en gardant un investissement en développement réduit (grâce à ladite architecture). Il sera temps d'investir cette fois dans de l'optimisation au cas par cas tout en ayant une idée des volumes en jeu et des informations de monitoring sur les goulôts d'étranglement. Cela permettra de choisir une alternative de manière éclairée. Elle est pas belle la vie ? 😉
Comment bien démarrer ?
Le starter-kit de subzero (l'équivalent de PostgREST mais qui offre aussi GraphQL par dessus) est un excellent point de départ !
Un nouveau produit (open-source !) a fait son apparition sur le marché : Hasura. Sa courbe d'apprentissage est bien plus aisée que PostgREST (sur l'aspect initialisation du projet) car il expose une interface graphique pour créer ses différentes tables, déclarer les dépendances et propose un premier niveau de gestion de permission. C'est moins violent que de partir directement sur des migrations SQL pour les nouveaux arrivants. Hasura expose le tout sous forme d'API GraphQL (avec support des subscriptions temps-réel sans code supplémentaire !) et un support des webhooks for-free, faites vous plaisir!
Pour mysql il y a xmysql, même logique que PostgREST mais qui ne respecte pas SoC (Separation of Concerns), il fait papa/maman (upload de fichiers, génération de graphique, ...), bien pour prototyper mais je ne le recommanderais pas pour de la production.
J'ai commencé à écrire un livre sur "tout ce que j'aurais aimé connaitre avant d'être CTO" (nom temporaire) "D'un petit SaaS à forte croissance à une très grande entreprise".
C'est une collection de tous les principes et patterns que j'ai pu découvrir depuis 2012, allant de la spécification de l'organisation, de la mise à l'échelle des processus internes, du staffing et sourcing, du management, de la gestion de la production, des choix, avec bien sûr une large partie concernant le pendant technique et l'affinage d'une vision. Ces dernières années beaucoup de collègues m'ont demandé de réunir ces principes au sein d'un même endroit... nous y voilà ! J'espère terminer ce livre avant mon 30ème anniversaire (juste pour le challenge), il reste encore 9 mois et les principes fondamentaux que je répète chaque jour au travail sont là.
Le formulaire ci-dessous te permettra d'être notifié de sa publication 🐣!
Merci à David Sferruzza et Audrey Cambert pour leur relecture !
It's been a while since my last blog post, I've been working hard on improving Image-Charts these past months as well as structuring my professional (at Ouest-France) and personal life with GTD.
I'm starting to share numbers about my SaaS, so without further ado, here are the last reports for Image-Charts 🦄
Image-charts July 2018 report:
— Image Charts (@imagecharts) August 7, 2018
📊 1 million generated charts
🦄 ... including 65K animated gif
💫 ... and 31K in webp format
🏎 284ms avg. response time
🗺 156 countries served around the globe
💰 +35% gross volume
Use it, it's free! https://t.co/o7n7YofPmx
🦄 Image-charts August 2018 report
— Image Charts (@imagecharts) September 4, 2018
📊 +16% traffic (1,16 million generated charts)
💰 +92% gross volume 💵🚀
🍥 *New* polar area chart, cht=pa
🌟 *New* data format, chd=e:
🎢 *New* data labels, chlhttps://t.co/ylUqGF9mYD
🦄 Image-charts September 2018 report
— Image Charts (@imagecharts) October 2, 2018
🛁 New: Bubble charts!
🐙 New: Graph-Viz charts!
🐣 First customer on yearly plan
💵 x2 gross between Q2 & Q3
⛑ +4% test coverage (97% overall)https://t.co/yHTd6hnlX8 pic.twitter.com/qYlbSO7RtW
Oh, one last thing 😅📚! I started to write a book about (temporary title) "everything I wish I had known before being a CTO" "From a small SaaS with huge growth to a large corporation"
It's a collection of every principle and patterns I've discovered since 2012 from organization specification, internal process scaling, resource/staffing, management, operations, choices, with of course a large part on the technical-side and vision. These past years a lot of colleagues asked me to gather them in a single place so here we are! I wish to complete it before my 30th birthday (just for fun), I've still got 9 months to go and at that point gathered the main principles I repeat at work everyday.
Subscribe below to be notified when it's published 🐣!
Original post on blog.redsmin.com
Like any SaaS business, Redsmin has to manage customer payments. To that end, I always use Stripe, an online payment gateway with an awesome developer experience (DX).
1 year after Redsmin’s initial launch, back in December 2014, I also subscribed to Stunning to manage pre-dunning, dunning email and easily set up a page allowing my clients to update their payment details.
However, when I took a look at my fixed expenses over the past 4 years, I noticed that a nonanecdotal part of our fixed expenses were directly allocated to Stunning. As I launch almost one new SaaS business every year, and that Image-Charts’ customers were already asking me to update their credit card information, I had to take action. Either buy another Stunning account or do-what-I-always-do: build from scratch a service that handles it for me… Thus migrating Redsmin from Stunning to this new service written from scratch.
That's how the idea to build a reusable piece of software came to mind: Stripe-update-card was born.

As I'm progressively moving my stack from NodeJS ecosystem to Rust, I had to fix some issues on stripe-rs library. Besides this, everything went fine and the service has been written and deployed on CleverCloud in a day (awesome service, give it a try!). Stripe-update-card on Github, PRs are welcome!
I wanted this microservice to be very simple yet fully customizable to be usable inin many products. It's already used in production at Redsmin, Image-Charts and will be deployed in the coming months on KillBug and GetSignature (but that’s another story).
Stripe-update-card’s form is fully customizable, only 3 environment variables are required to start the service (STRIPE_PUBLISHABLE_KEY, STRIPE_SECRET_KEY and SUCCESS_REDIRECT_URL). You can use the others to better promote your brand, product description, logo and so on.
docker run -it \
-e STRIPE_PUBLISHABLE_KEY=pk_test_xxx \
-e STRIPE_SECRET_KEY=sk_test_xxx \
-e SUCCESS_REDIRECT_URL=https://url.to.redirect/on/success \
-p 8080:8080 \
fgribreau/stripe-update-cardI'm pretty sure other indie/SaaS hackers will find it useful (instead of rewriting it from scratch every time). If so, don't hesitate to reach out and please send a PR to update "Running in production" README section!
Kubernetes events stream with kubectl get events --all-namespaces --watch are very hard to read, unless you got a very very (very) large screen.
NAMESPACE LAST SEEN FIRST SEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
image-charts 2018-05-03 20:36:08 +0200 CEST 2018-05-03 20:36:08 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b364506573f50 Pod Normal Scheduled default-scheduler Successfully assigned image-charts-deployment-57575d876f-5vjvj to gke-image-charts-us-w-production-pool-09fa8042-gmcd
image-charts 2018-05-03 20:36:09 +0200 CEST 2018-05-03 20:36:09 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b36451cb11f32 Pod Normal SuccessfulMountVolume kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd MountVolume.SetUp succeeded for volume "default-token-psj7t"
image-charts 2018-05-03 20:36:11 +0200 CEST 2018-05-03 20:36:11 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b3645963079f5 Pod spec.containers{image-charts-runner} Normal Pulled kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Container image "eu.gcr.io/ic-18/image-charts:master-ef08ceeaf315c89f7e7dd4bc4cec8f9b0cef834a" already present on machine
image-charts 2018-05-03 20:36:11 +0200 CEST 2018-05-03 20:36:11 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b364599f0352e Pod spec.containers{image-charts-runner} Normal Created kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Created container
image-charts 2018-05-03 20:36:12 +0200 CEST 2018-05-03 20:36:12 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b3645c253b80f Pod spec.containers{image-charts-runner} Normal Started kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Started container
image-charts 2018-05-03 20:42:08 +0200 CEST 2018-05-03 20:42:08 +0200 CEST 1 image-charts-deployment-57575d876f-5vjvj.152b3698d837ff3c Pod spec.containers{image-charts-runner} Normal Killing kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Killing container with id docker://image-charts-runner:Need to kill Pod
image-charts 2018-05-03 20:20:38 +0200 CEST 2018-05-03 20:20:38 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b356c77a29f53 Pod Normal Scheduled default-scheduler Successfully assigned image-charts-deployment-57575d876f-v74c8 to gke-image-charts-us-w-production-pool-09fa8042-gmcd
image-charts 2018-05-03 20:20:39 +0200 CEST 2018-05-03 20:20:39 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b356c88794874 Pod Normal SuccessfulMountVolume kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd MountVolume.SetUp succeeded for volume "default-token-psj7t"
image-charts 2018-05-03 20:20:40 +0200 CEST 2018-05-03 20:20:40 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b356ce43ac4e3 Pod spec.containers{image-charts-runner} Normal Pulled kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Container image "eu.gcr.io/ic-18/image-charts:master-ef08ceeaf315c89f7e7dd4bc4cec8f9b0cef834a" already present on machine
image-charts 2018-05-03 20:20:40 +0200 CEST 2018-05-03 20:20:40 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b356ceadd2e40 Pod spec.containers{image-charts-runner} Normal Created kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Created container
image-charts 2018-05-03 20:20:41 +0200 CEST 2018-05-03 20:20:41 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b356d1403821b Pod spec.containers{image-charts-runner} Normal Started kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Started container
image-charts 2018-05-03 20:26:09 +0200 CEST 2018-05-03 20:26:09 +0200 CEST 1 image-charts-deployment-57575d876f-v74c8.152b35b95bfa97e4 Pod spec.containers{image-charts-runner} Normal Killing kubelet, gke-image-charts-us-w-production-pool-09fa8042-gmcd Killing container with id docker://image-charts-runner:Need to kill Pod
image-charts 2018-05-03 20:20:38 +0200 CEST 2018-05-03 20:20:38 +0200 CEST 1 image-charts-deployment-57575d876f.152b356c778b2a36 ReplicaSet Normal SuccessfulCreate replicaset-controller Created pod: image-charts-deployment-57575d876f-v74c8
image-charts 2018-05-03 20:26:08 +0200 CEST 2018-05-03 20:26:08 +0200 CEST 1 image-charts-deployment-57575d876f.152b35b94cd06d75 ReplicaSet Normal SuccessfulDelete replicaset-controller Deleted pod: image-charts-deployment-57575d876f-v74c8
image-charts 2018-05-03 20:36:08 +0200 CEST 2018-05-03 20:36:08 +0200 CEST 1 image-charts-deployment-57575d876f.152b364505f8a022 ReplicaSet Normal SuccessfulCreate replicaset-controller Created pod: image-charts-deployment-57575d876f-5vjvj
image-charts 2018-05-03 20:42:08 +0200 CEST 2018-05-03 20:42:08 +0200 CEST 1 image-charts-deployment-57575d876f.152b3698d19cba5f ReplicaSet Normal SuccessfulDelete replicaset-controller Deleted pod: image-charts-deployment-57575d876f-5vjvj
image-charts 2018-05-03 20:42:08 +0200 CEST 2018-05-03 12:27:10 +0200 CEST 21 image-charts-deployment.152b1b9630769766 Deployment Normal ScalingReplicaSet deployment-controller Scaled down replica set image-charts-deployment-57575d876f to 3
image-charts 2018-05-03 20:36:08 +0200 CEST 2018-05-03 12:47:08 +0200 CEST 20 image-charts-deployment.152b1cad1828a4bc Deployment Normal ScalingReplicaSet deployment-controller Scaled up replica set image-charts-deployment-57575d876f to 4
image-charts 2018-05-03 20:36:08 +0200 CEST 2018-04-23 22:32:29 +0200 CEST 205 image-charts-hpa.15282ad08af5393c HorizontalPodAutoscaler Normal SuccessfulRescale horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
image-charts 2018-05-03 20:42:08 +0200 CEST 2018-04-23 22:38:29 +0200 CEST 205 image-charts-hpa.15282b2472554668 HorizontalPodAutoscaler Normal SuccessfulRescale horizontal-pod-autoscaler New size: 3; reason: All metrics below target
Let's specify a go-template and improve this:
kubectl get events --all-namespaces --watch -o 'go-template={{.lastTimestamp}} {{.involvedObject.kind}} {{.message}} ({{.involvedObject.name}}){{"\n"}}'
2018-05-03T18:36:08Z Pod Successfully assigned image-charts-deployment-57575d876f-5vjvj to gke-image-charts-us-w-production-pool-09fa8042-gmcd (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:36:09Z Pod MountVolume.SetUp succeeded for volume "default-token-psj7t" (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:36:11Z Pod Container image "eu.gcr.io/killbug-165718/image-charts:master-ef08ceeaf315c89f7e7dd4bc4cec8f9b0cef834a" already present on machine (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:36:11Z Pod Created container (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:36:12Z Pod Started container (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:42:08Z Pod Killing container with id docker://image-charts-runner:Need to kill Pod (image-charts-deployment-57575d876f-5vjvj)
2018-05-03T18:20:38Z Pod Successfully assigned image-charts-deployment-57575d876f-v74c8 to gke-image-charts-us-w-production-pool-09fa8042-gmcd (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:20:39Z Pod MountVolume.SetUp succeeded for volume "default-token-psj7t" (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:20:40Z Pod Container image "eu.gcr.io/killbug-165718/image-charts:master-ef08ceeaf315c89f7e7dd4bc4cec8f9b0cef834a" already present on machine (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:20:40Z Pod Created container (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:20:41Z Pod Started container (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:26:09Z Pod Killing container with id docker://image-charts-runner:Need to kill Pod (image-charts-deployment-57575d876f-v74c8)
2018-05-03T18:20:38Z ReplicaSet Created pod: image-charts-deployment-57575d876f-v74c8 (image-charts-deployment-57575d876f)
2018-05-03T18:26:08Z ReplicaSet Deleted pod: image-charts-deployment-57575d876f-v74c8 (image-charts-deployment-57575d876f)
2018-05-03T18:36:08Z ReplicaSet Created pod: image-charts-deployment-57575d876f-5vjvj (image-charts-deployment-57575d876f)
2018-05-03T18:42:08Z ReplicaSet Deleted pod: image-charts-deployment-57575d876f-5vjvj (image-charts-deployment-57575d876f)
2018-05-03T18:42:08Z Deployment Scaled down replica set image-charts-deployment-57575d876f to 3 (image-charts-deployment)
2018-05-03T18:36:08Z Deployment Scaled up replica set image-charts-deployment-57575d876f to 4 (image-charts-deployment)
2018-05-03T18:36:08Z HorizontalPodAutoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target (image-charts-hpa)
2018-05-03T18:42:08Z HorizontalPodAutoscaler New size: 3; reason: All metrics below target (image-charts-hpa)
Much better right?
Last thing, we do not want to remember this so let's define a function in ~/.zshrc (or equivalent):
kubectl-events() {
kubectl get events --all-namespaces --watch -o 'go-template={{.lastTimestamp}} {{.involvedObject.kind}} {{.message}} ({{.involvedObject.name}}){{"\n"}}'
}
Done 👍
Note: if you wish to be a Kubernetes power-user take a look at kubectx cli!
Special thanks to @m_pousse that wrote the initial go-template version based on a kubernetes event stream app I was working on!
Who doesn't want to spread one of its SaaS across continents? I finally had the opportunity to do it for my Image-Charts SaaS!
Image-charts was at first hosted on a Kubernetes cluster in europe-west Google Cloud Engine region and it was kind of an issue considering where our real users where (screenshot courtesy of Cloudflare DNS traffic):
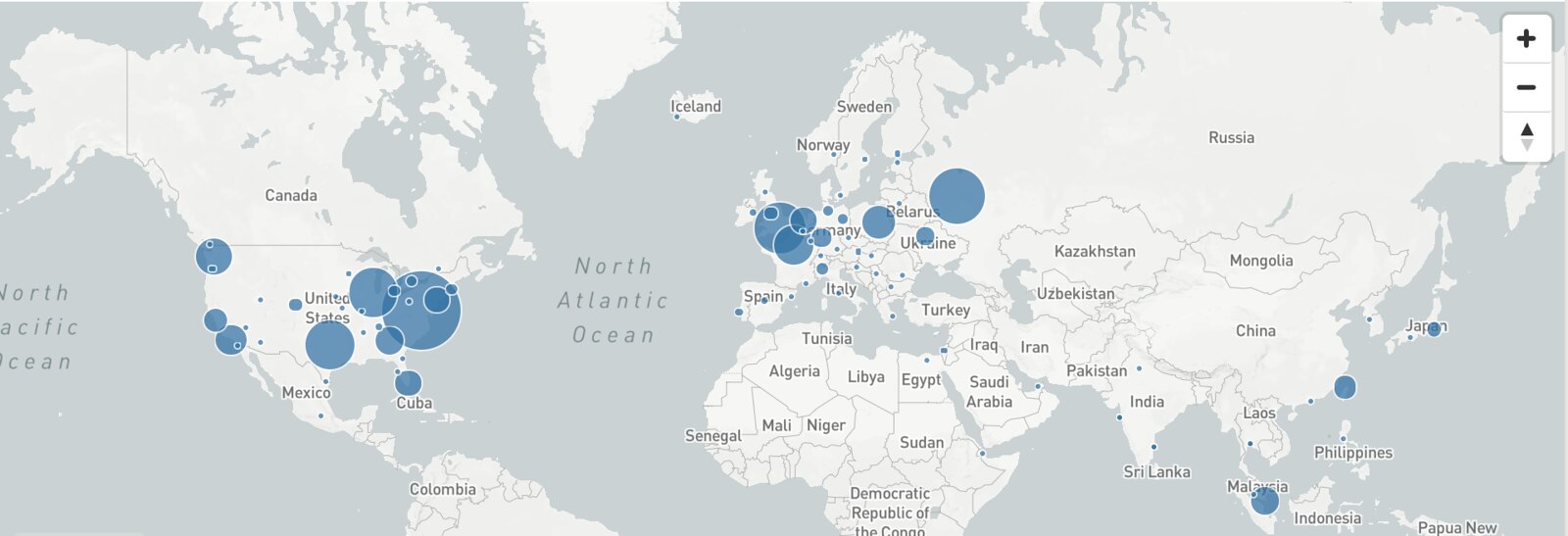
As we can see, an important part of our traffic come from the US zone. Good news, it was time to try multi-region kubernetes. Here is a step by step guide on how to do it.
First thing first, let's create a new kubernetes cluster in us-west coast:
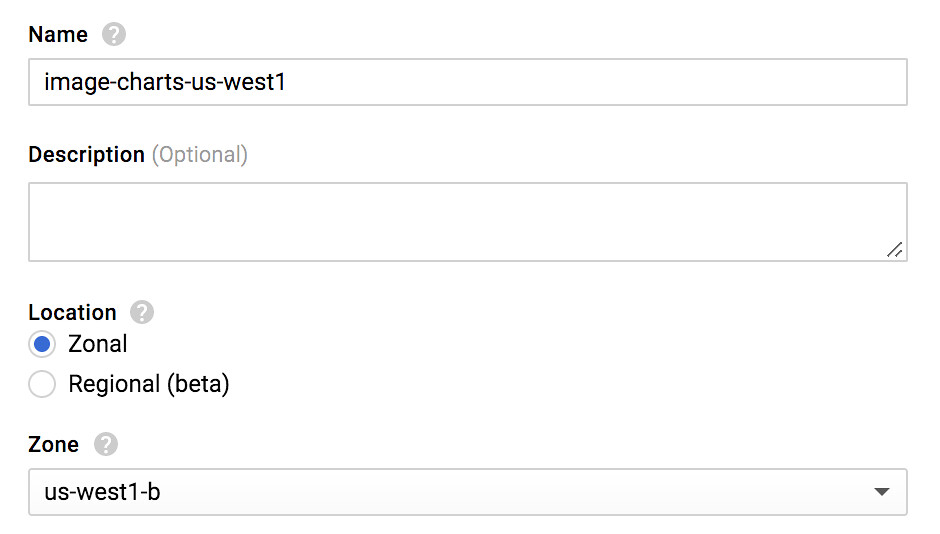
You should really (really) enable the preemptible nodes feature. Why? Because you get chaos engineering for free and continuously test your application architecture and configuration for robustness! Preemptible VM means that cluster nodes won't last more than 24 hours and good news : I observed cluster cost reduction by two.

Next we need to create a new IP address on GCE. We will associate this IP to our kubernetes service so it will always stay with a static IP.
gcloud compute addresses create image-charts-us-west1 --region us-west1
Wait for it...
gcloud compute addresses list NAME REGION ADDRESS STATUS image-charts-europe-west1 europe-west1 35.180.80.101 RESERVED image-charts-us-west1 us-west1 35.180.80.100 RESERVED
The above app YAML defines multiple Kubernetes objects: a namespace (app-ns), a service that will give access to our app from outside (my-app-service), our app deployment object (my-app-deployment), auto-scaling through horizontal pod autoscaler and finally a pod disruption budget for our app.
# deploy/k8s.yaml
apiVersion: v1
kind: Namespace
metadata:
name: app-ns
---
apiVersion: v1
kind: Service
metadata:
labels:
app: my-app
zone: __ZONE__
name: my-app-service
namespace: app-ns
spec:
type: NodePort
ports:
- name: "80"
port: 80
targetPort: 8080
protocol: TCP
selector:
app: my-app
type: LoadBalancer
loadBalancerIP: __IP__
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
namespace: app-ns
name: my-app-deployment
labels:
app: my-app
spec:
replicas: 3
# how much revision history of this deployment you want to keep
revisionHistoryLimit: 2
strategy:
type: RollingUpdate
rollingUpdate:
# specifies the maximum number of Pods that can be unavailable during the update
maxUnavailable: 25%
# specifies the maximum number of Pods that can be created above the desired number of Pods
maxSurge: 200%
template:
metadata:
labels:
app: my-app
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
topologyKey: "kubernetes.io/hostname"
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-app
restartPolicy: Always
containers:
- image: __IMAGE__
name: my-app-runner
resources:
requests:
memory: "100Mi"
cpu: "1"
limits:
memory: "380Mi"
cpu: "2"
# send traffic when:
readinessProbe:
httpGet:
path: /_ready
port: 8081
initialDelaySeconds: 20
timeoutSeconds: 4
periodSeconds: 5
failureThreshold: 1
successThreshold: 2
# restart container when:
livenessProbe:
httpGet:
path: /healthz
port: 8081
initialDelaySeconds: 20
timeoutSeconds: 2
periodSeconds: 2
# if we just started the pod, we need to be sure it works
# so it may take some time and we don't want to rush things up (thx to rolling update)
failureThreshold: 5
successThreshold: 1
ports:
- name: containerport
containerPort: 8080
- name: monitoring
containerPort: 8081
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
namespace: app-ns
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: my-app-deployment
minReplicas: 3
maxReplicas: 5
targetCPUUtilizationPercentage: 200
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: my-app-pdb
namespace: app-ns
spec:
minAvailable: 2
selector:
matchLabels:
app: my-app
Some things of note:
__IMAGE__, __IP__ and __ZONE__ will be replaced during the gitlab-ci deploy stage (see continuous delivery pipeline section).
kind: Service # [...] type: LoadBalancer loadBalancerIP: __IP__
type: LoadBalancer and loadBalancerIP tell kubernetes to creates a TCP Network Load Balancer (the IP must be a regional one, just as we did).
It's always a good practice to split up monitoring and production traffic that's why monitoring is on port 8081 (for liveness and readiness probes) and production traffic on port 8080.
Another good practice is to setup podAntiAffinity to tell kubernetes scheduler to place our app pod replica between available nodes and not put all our app pods on the same node.
And the good news is: this principle can be easily applied in Kubernetes thanks to requests and limits.
Finally we use PodDisruptionBudget policy to tell Kubernetes scheduler how to react when disruptions occurs (e.g. one of our preemptible node dies).
I used Gitlab-CI here because that's what power Image-charts & Redsmin deployments but it will work with other alternatives as well.
# gitlab.yaml
# https://docs.gitlab.com/ce/ci/yaml/
image: docker
# fetch is faster as it re-uses the project workspace (falling back to clone if it doesn't exist).
variables:
GIT_STRATEGY: fetch
# We use overlay for performance reasons
# https://docs.gitlab.com/ce/ci/docker/using_docker_build.html#using-the-overlayfs-driver
DOCKER_DRIVER: overlay
services:
- docker:dind
stages:
- build
- test
- deploy
# template that we can reuse
.before_script_template: &setup_gcloud
image: lakoo/node-gcloud-docker:latest
retry: 2
variables:
# default variables
ZONE: us-west1-b
CLUSTER_NAME: image-charts-us-west1
only:
# only
- /master/
before_script:
- echo "Setting up gcloud..."
- echo $GCLOUD_SERVICE_ACCOUNT | base64 -d > /tmp/$CI_PIPELINE_ID.json
- gcloud auth activate-service-account --key-file /tmp/$CI_PIPELINE_ID.json
- gcloud config set compute/zone $ZONE
- gcloud config set project $GCLOUD_PROJECT
- gcloud config set container/use_client_certificate False
- gcloud container clusters get-credentials $CLUSTER_NAME
- gcloud auth configure-docker --quiet
after_script:
- rm -f /tmp/$CI_PIPELINE_ID.json
build:
<<: *setup_gcloud
stage: build
retry: 2
script:
- docker build --rm -t ${DOCKER_REGISTRY}/${PACKAGE_NAME}:${CI_COMMIT_REF_NAME}-${CI_COMMIT_SHA} .
- mkdir release
- docker push ${DOCKER_REGISTRY}/${PACKAGE_NAME}:${CI_COMMIT_REF_NAME}-${CI_COMMIT_SHA}
test:
<<: *setup_gcloud
stage: test
coverage: '/Lines[^:]+\:\s+(\d+\.\d+)\%/'
retry: 2
artifacts:
untracked: true
expire_in: 1 week
name: "coverage-${CI_COMMIT_REF_NAME}"
paths:
- coverage/lcov-report/
script:
- echo 'edit me'
.job_template: &deploy
<<: *setup_gcloud
stage: deploy
script:
- export IMAGE=${DOCKER_REGISTRY}/${PACKAGE_NAME}:${CI_COMMIT_REF_NAME}-${CI_COMMIT_SHA}
- cat deploy/k8s.yaml | sed s#'__IMAGE__'#$IMAGE#g | sed s#'__ZONE__'#$ZONE#g | sed s#'__IP__'#$IP#g > deploy/k8s-generated.yaml
- kubectl apply -f deploy/k8s-generated.yaml
- echo "Waiting for deployment..."
- (while grep -v "successfully" <<<$A]; do A=`kubectl rollout status --namespace=app-ns deploy/my-app-deployment`;echo "$A\n"; sleep 1; done);
artifacts:
untracked: true
expire_in: 1 week
name: "deploy-yaml-${CI_COMMIT_REF_NAME}"
paths:
- deploy/
deploy-us:
<<: *deploy
variables:
ZONE: us-west1
CLUSTER_NAME: image-charts-us-west1
IP: 35.180.80.100
deploy-europe:
<<: *deploy
variables:
ZONE: europe-west1
CLUSTER_NAME: image-charts-europe-west1
IP: 35.180.80.101
Here are the environment variables to setup in Gitlab-CI pipeline settings UI:

DOCKER_REGISTRY (e.g. eu.gcr.io/project-100110): container registry to use, easiest way is to leverage GCE container registry.
GCLOUD_PROJECT (e.g. project-100110): google cloud project name.
GCLOUD_SERVICE_ACCOUNT: a base64 encoded service account JSON. When creating a new service account on GCE console you will get a JSON like this:
{
"type": "service_account",
"project_id": "project-100110",
"private_key_id": "1000000003900000ba007128b770d831b2b00000",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvgIBADANBgkqhkiG9w0BAQE\nhOnLxQa7qPrZFLP+2S3RaSudsbuocVo4byZH\n5e9gsD7NzsD/7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n7ECJDyInbH8+MEJxFBW/yYUX6XHM/d\n5OijyIdA4+NPo6KpkJa2WV8I/KPtoNLSK7d6oRdEAZ\n\n-----END PRIVATE KEY-----\n",
"client_email": "gitlab@project-100110.iam.gserviceaccount.com",
"client_id": "118000107442952000000",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/gitlab%40project-100110.iam.gserviceaccount.com"
}
To make it work on our CI, we need to transform it to base64 in order to inject it as an environment variable.
cat service_account.json | base64
PACKAGE_NAME (e.g. my-app): container image name.
The YAML syntax below defines a template...
.before_script_template: &setup_gcloud
... that we can then reuse with:
<<: *setup_gcloud
I'm particularly fond of the one-liner below that makes gitlab-ci job wait for deployment completion:
(while grep -v "successfully" <<<$A]; do A=`kubectl rollout status --namespace=app-ns deploy/my-app-deployment`;echo "$A\n"; sleep 1; done);
One line to wait for kubernetes rolling-update to complete, fits perfectly inside @imagecharts Continuous Deployment Pipeline pic.twitter.com/9Q6gRwdMiX
— François-G. Ribreau (@FGRibreau) April 9, 2018
It's so simple and does the job.
Note: the above pipeline only runs when commits are pushed to master, I removed other environments code for simplicity.
The important part is:
deploy-us:
<<: *deploy
variables:
ZONE: us-west1
CLUSTER_NAME: image-charts-us-west1
IP: 35.180.80.100
This is where the magic happens, this job includes shared deploy job template (that itself includes setup_gcloud template) and specify three variables: the ZONE, CLUSTER_NAME and the IP address to expose) that alone is sufficient to make our pipeline deploy to multiple Kubernetes cluster on GCE. Bonus: we store the generated YAML as an artifact for future inspections.
Pushing our code you should have something like this:
Now lets connect to one of our kubernetes cluster. Tips: to easily switch between kubectl context I use kubectx

# on us-west1 cluster kubectl get service/my-app-service -w --namespace=image-charts NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-app-service LoadBalancer 10.59.250.180 35.180.80.100 80:31065/TCP 10s
From this point you should be able to access both public static IP with curl.
Same warning as before, I used Cloudflare for the geo-dns part but you could use another provider. It costs $25/mo to get basic geo-dns load-balancing between region: basic load balancing ($5/mo), up to 2 origin servers ($0/mo), check every 60 seconds ($0/mo), check from 4 regions ($10/mo), geo routing ($10/mo).
Once activated, create a two pools (one per region using the static IP we just created):
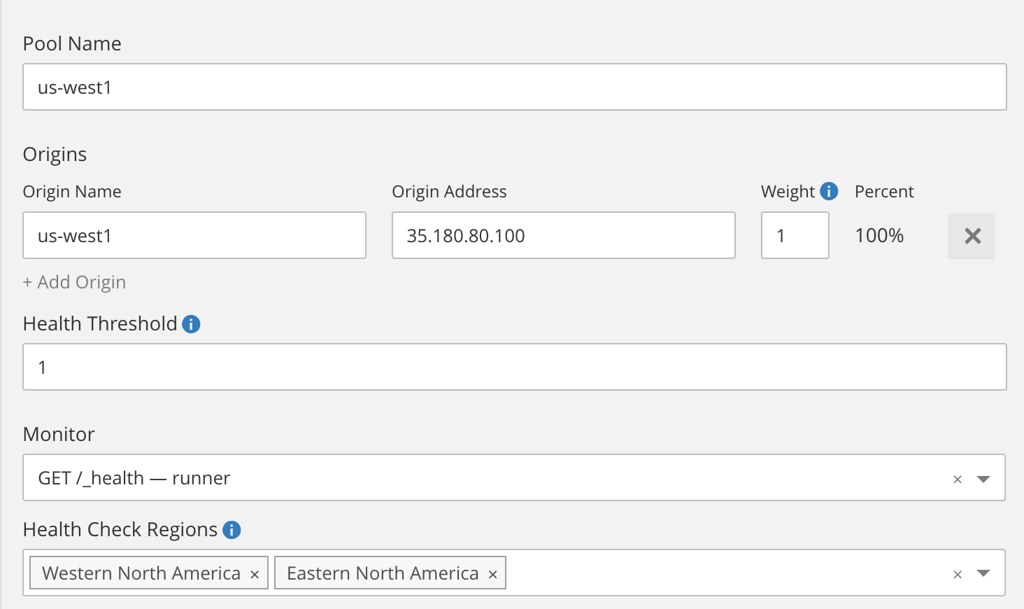
... then create a monitor and finally the load-balancer that distribute load based on the visitor geolocation.
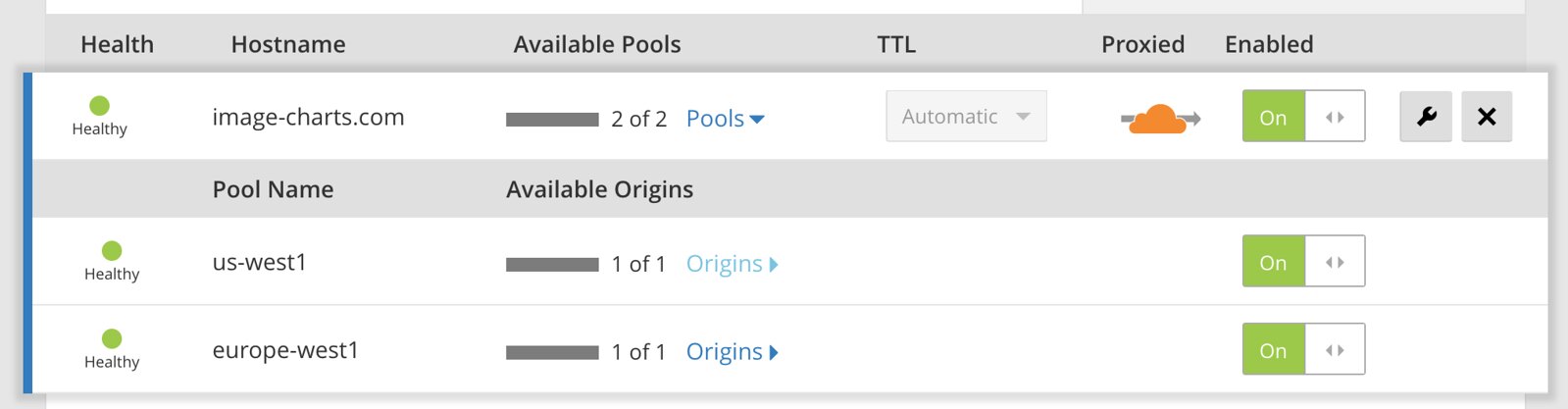
And... we're done 🎉
Since ~2000 I always setup a "/labs" folder on new computers. I use it to quickly start new projects and experiments.
Even if I have continuous backup in place through Backblaze, I wanted, for non-public & non-open-source projects to be able to quickly sync/backup them to Gitlab... and that's what this script do.
I spent only 2 hours tonight migrating Image-Charts website from gulp to the amazing Parcel.
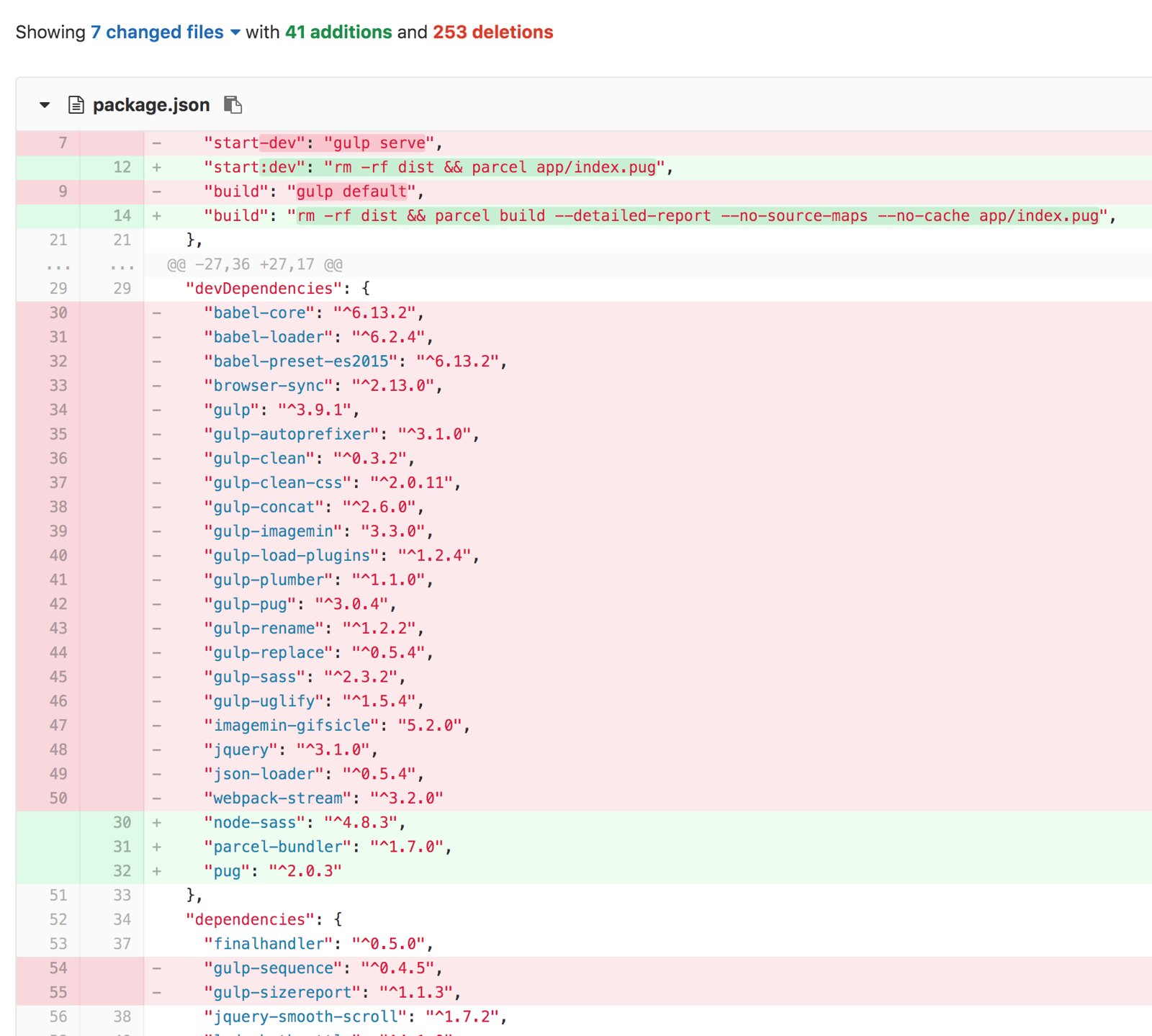
Before:

After:

Before:
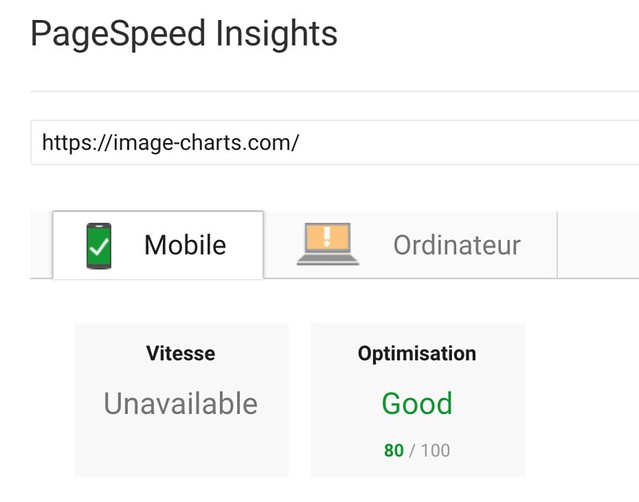
After:
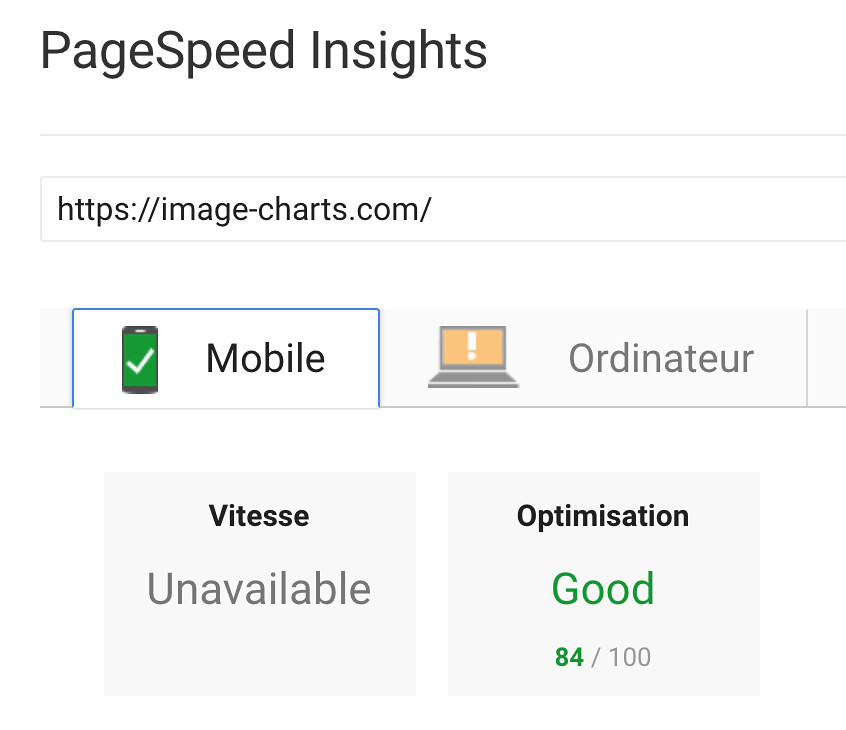
WAY less code, one cli that automatically created the dependencies tree starting from my main pug file, imported build packages (pug and node-sass) and created a state-of-the-art dist directory. Fast by design.
I had this weird cargo error while trying to publish a new Mailchecker rust crate version and could not find anything on Google about.
Updating registry `https://github.com/rust-lang/crates.io-index`
error: failed to update registry `https://github.com/rust-lang/crates.io-index`
Caused by:
failed to fetch `https://github.com/rust-lang/crates.io-index`
Caused by:
invalid pack file - invalid packfile type in header; class=Odb (9)
I removed the local registry copy and it worked:
rm -rf ~/.cargo/registry
I know it's a little late but I wondered this morning : would it be nice to make a recap of 2017 using only my Github, Instagram and Twitter accounts, so here we are!
I started 2017 playing with HTML Audio API, building real-time sound analysis and visualizations.
But this was mostly for entertainment, on the business side I was working on the architecture of the upcoming KillBug SaaS...
... and the user workflow with @EmmanuelJulliot.
I finally bought a LaMetric and started to play with it...
Later that year, during (another!) breakfast I built rss-to-lametric that displays latest Rss news directly from LaMetric!
Took the breakfast to make a @OuestFrance app for my @getlametric (one-shot deploy /w @clever_cloud), can't wait to activate it! pic.twitter.com/Pze8p2bhoD
— François-G. Ribreau (@FGRibreau) November 2, 2017
The NodeJS version was great but not good enough. I've rewrote it in Rust 2 days laters, released it on Github and published multiple lametric apps with it!
Took the breakfast to make a @OuestFrance app for my @getlametric (one-shot deploy /w @clever_cloud), can't wait to activate it! pic.twitter.com/Pze8p2bhoD
— François-G. Ribreau (@FGRibreau) November 2, 2017
... without knowing I would receive a Cease and Desist letter from 20 minutes because I used 20 Minutes logo, copyright stupidity.
[Fr] J'ai reçu une "Cease and desist letter" de @20Minutes pour mon app LaMetric. Bizarrement WP ou NYT ne bronchent pas, la *stupidité* du copyright. pic.twitter.com/zG0KcE1UzE
— François-G. Ribreau (@FGRibreau) December 11, 2017
In March I redesigned fgribreau.com so it could share testimonials about my advisory activities. The site source-code is now hosted on Github and served through Netlify.
Still in March, we've deploy KillBug on a Google Cloud Kubernetes cluster and I made a cost parsing little tool for it (now I use ReOptimize for that)
In April I sold RedisWekely newsletter to Redis Labs, a newsletter I started in 2013 that reached thousands of subscribers.
I also started to get back on wood work...
at that time I did not know that I would build my very own table in August!
In the same month I've left iAdvize to join Ouest-France as head of digital development and architect. Elon Musk bibliography was an awesome read.
... and I also read that
... and this one ...
[Fr] message pour les RH/DSI, on peut faire un joli parallèle entre l’analyse de Machiavel sur posséder une armée vs posséder des mercenaires
— François-G. Ribreau (@FGRibreau) December 31, 2017
ET recruter une équipe vs recruter des prestataires pic.twitter.com/gCGOVv2Yzw
... and this one...
« Practice disobedience » pic.twitter.com/IlP2nKxNmb
— François-G. Ribreau (@FGRibreau) December 13, 2017
[Fr] Lectures de la semaine prochaine ! #vacances pic.twitter.com/dG77yx5kRM
— François-G. Ribreau (@FGRibreau) December 22, 2017
... and this one...
... and that’s why transparency is key in mid/big enterprise. Working everyday in that direction, already saw great improvements/consequences. pic.twitter.com/Q74nxRkbyY
— François-G. Ribreau (@FGRibreau) December 20, 2017
... and these ones (and lot of other books that I did not share on Instagram 😅)...
10 days after my arrival at Ouest-France I "hacked into" active directory to map the organisational chart because I could not find an up to date one and here is the result I had...
One other thing that bothered me was that some internal software (e.g. Redmine) at Ouest-France were not available programmatically from outside because of an old version of Microsoft ISA-server redirecting to an auth form and thus blocking requests. So I wrote a little tool that proxy requests and rewrite them to pass Microsoft ISA server gateway and let us finally automate things on top of internal software like Redmine.
In the last three month of every year since 2014, I always work on improving HeyBe. Heybe is a SaaS that let companies generate personalized video at scale for their customers. This year, I migrated HeyBe video generation cluster to Google Cloud, wrote my own Google Cloud Group Instance auto-scaler for our custom need in Rust.
Does it scale? Yes. 🚀
— François-G. Ribreau (@FGRibreau) November 6, 2017
(Google Cloud instance group (quota upgraded 🎉) fully controlled by a #Rust program monitoring a RabbitMQ queue) pic.twitter.com/iopiXitIcA
I released a simple Google Cloud API client in Rust...
Just released the v0.1.0 of my Google Cloud API @rustlang client that handle instance group resize for me :) https://t.co/9PXmrB8UyG pic.twitter.com/obkPK5R4IH
— François-G. Ribreau (@FGRibreau) October 29, 2017
... and a NodeJS stringify equivalent in Rust.
... and also a very (very) small rust library that stringify querystring (could not find one) https://t.co/DKugxMfBsm pic.twitter.com/G85tJ9qD57
— François-G. Ribreau (@FGRibreau) October 29, 2017
Heybe 2017 release was then ready for prime-time!
[Fr] Le fameux service sur lequel cette année j'ai travaillé à mettre en place de l'auto-scaling (géré en @rustlang) sur Google Cloud pour la génération des vidéos 👌 https://t.co/tVzp44nQFt
— François-G. Ribreau (@FGRibreau) January 2, 2018
Moving cluster to Google Cloud largely reduced HeyBe fixed costs as well.
Dropped the operating cost for one of my startup from 1 500€/month to 152€/month.
— François-G. Ribreau (@FGRibreau) December 7, 2017
- moved from a 3 servers bare-metal hosting to Google Cloud
- leveraged elasticity (automatically scaling up to 30 servers)
- reduced costs for end users pic.twitter.com/Pt3cdrzRjI
For the past 5 years I do still follow hacker philosophy and share what I learn, here I gave a lecture at Nantes University about NoSQL.
and there at Ouest-France about Kubernetes philosophy and Containers
I worked on KillBug and wrote code for the animated background...
... and discovered that Google Cloud was blocking outbound connections to ports 25, 465 and 587....
GKE does not allow outbound connections on ports 25, 465, 587. Keycloak requires SMTP. I need to build a SMTP to SendGrid API gateway. pic.twitter.com/Ok1tsMsu7o
— François-G. Ribreau (@FGRibreau) September 2, 2017
... so I wrote a little SMTP proxy to fix it...
SMTP to @SendGrid Gateway 💫 (bypass GKE limitation) https://t.co/FOFcuoqHAE pic.twitter.com/0ngsjIVQTP
— François-G. Ribreau (@FGRibreau) September 3, 2017
... and also built a PostgreSQL to AMQP tool that forwards some pg_notify events to AMQP (RabbitMQ) for KillBug.
Some weeks later we opened KillBug first private beta
I went on improvising playing piano as well...
... and really enjoyed it ...
Saturday morning piano improvisation! 🎹 pic.twitter.com/nQbcTmJVqd
— François-G. Ribreau (@FGRibreau) September 16, 2017
In June, like every year (!) I went to Web2Day to give a talk about SaaS industrialization with OpenAPI/Swagger
Speaking about talk, I had the chance to give one (very unprepared) at Maia Matter in September, and two at Breizh Camp for my first attending.
During a travel to Paris I rewrote my NodeJS kubectx kubernetes little helper in Rust and saw impressive performance improvements.
Note: if you wish to see it in action, take a look at kubectx https://t.co/VtFDL5ncmX pic.twitter.com/GkIHVAmvsv
— François-G. Ribreau (@FGRibreau) December 26, 2017
In one August night I made my own clap recognition script with NodeJS and Philips Hue!
2017 was also the year I went back to electronics, bringing back souvenirs from childhood 😇
In October I started eating Huel every morning, as I'm taking my breakfast, writing these lines, I still do it today. It was a very impressive life-style change and I feel way more connected everyday since that day.
In October I also added custom domain name support to Image-Charts enterprise plan!
Image-charts enterprise plan now supports custom domain names! https://t.co/iXCp1LHXXv pic.twitter.com/SFTgNPT0Iq
— Image Charts (@imagecharts) October 15, 2017
Oh! And I also bought some Raspberry Pi and hacked a Magic Mirror!
In the mean time during that year I will wrote some code in Rust, like this Rust spinner library
[Release] Spinners - 60+ Elegant terminal spinners for @RustLang pic.twitter.com/2J8NmYBjAK
— François-G. Ribreau (@FGRibreau) December 18, 2017
Waiting for my Tesla 3, I bought a BMW x3 and asked them to send me the source code and how to subscribe as a developer to build widget for the onboard computer (but failed miserably!)
Just sent an mail to opensource@bmw.com to ask for source-code, wonder if I will find something interesting to hack over :) pic.twitter.com/ctN1DRDhKo
— François-G. Ribreau (@FGRibreau) December 26, 2017
However I got the source-code as a DVD AND pushed it on gitlab.com/fgribreau/bmw_oss!
So indeed, @BMW sends it’s OSS source code as a DVD, now I have to use my oldest MBP to read it... since I was able to send the email, a dl link would have been enough you know... pic.twitter.com/0zYfD9O269
— François-G. Ribreau (@FGRibreau) January 29, 2018
During December holidays I hacked on Ouest-France platform tooling
BlockProvider-example is 👌
— François-G. Ribreau (@FGRibreau) December 13, 2017
BlockProvider-runner is also 👌 pic.twitter.com/BbTEalOBpY
... wrote a JSON-schema documentation-generator
Ok so this upcoming json-schema-documentation-generator will use json-schema to define it's own options object and theme template input objects, validate them with ajv and use itself to generate its own documentation 🕺 pic.twitter.com/hGw1juLzAx
— François-G. Ribreau (@FGRibreau) December 31, 2017
... wrote some BlockProvider examples (I will give a talk at Breizh Camp about what they are, how they start to help bringing change to a large organization like Ouest-France and what an agnostic CMS is 😉)
BlockProvider-example is 👌
— François-G. Ribreau (@FGRibreau) December 13, 2017
BlockProvider-runner is also 👌 pic.twitter.com/BbTEalOBpY
The json-schema documentation generator now documents itself 🎉 https://t.co/OUdB1uLHqS pic.twitter.com/aUvAh6hvJr
— François-G. Ribreau (@FGRibreau) December 31, 2017
And a validator-cli for the upcoming Ouest-France platform
.@OuestFrance —to-be-announced— platform now has its own validator-cli (written in Rust) 🎉 https://t.co/oY8fH3oiPp …
— François-G. Ribreau (@FGRibreau) December 26, 2017
/cc @m_pousse @seb_brousse pic.twitter.com/vkwMv2d1OG
Lot of other things were released, updated or experimented during 2017. Let's make 2018 even better than 2017!